Um in paperless-ngx Dokumente zu importieren und OCR (Texterkennung) über jene laufen zu lassen, bedarf es einer kleinen Anpassung in den paperless-ngx-Einstellungen. Ohne die Änderung verweigert paperless-ngx und die genutzten Drittanwendungen das Einlesen des Textes mit der Meldung:
[2025-09-28 12:06:12,786] [WARNING] [paperless.parsing.tesseract] This file is encrypted and/or signed, OCR is impossible. Using any text present in the original file.
[2025-09-28 12:06:12,786] [WARNING] [paperless.parsing.tesseract] No text was found in /tmp/paperless/paperless-ngxey73_jza/samplecertifiedpdf.pdf, the content will be empty.
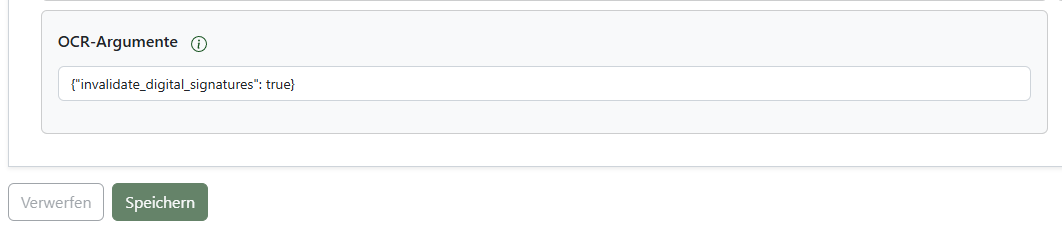
Unter „Konfiguration“ -> Reiter „OCR-Einstellungen“ > „OCR-Argumente“ muss die folgende Option in JSON-Format eingefügt werden:
{"invalidate_digital_signatures": true}
Sollten dort schon Einstellungen vorhanden sein, so müssen die JSON-Arrays entsprechend zusammengeführt werden.
Anschließend liest paperless-ngx die signierten Dateien ein, speichert das Original in signierter Form, aber speichert zusätzlich eine nicht mehr valide Datei (da sie verändert wurde) zum arbeiten in paperless-ngx in der entsprechenden Speicherpfad-Struktur.
DIe Warnmeldung wandelt sich um in:
[2025-09-28 12:14:00,368] [WARNING] [ocrmypdf._pipeline] All digital signatures will be invalidated
[2025-09-28 12:18:13,415] [WARNING] [ocrmypdf._pipeline] This PDF has a fillable form. Chances are it is a pure digital document that does not need OCR.
Schreibe einen Kommentar