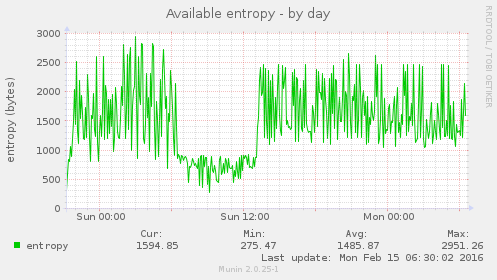
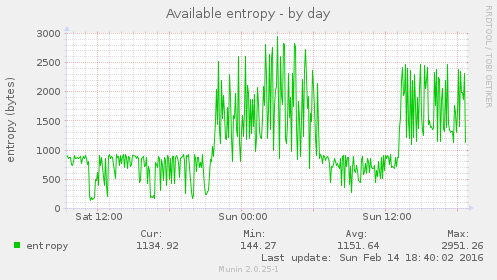
Es kann passieren, dass man in Dovecot zwar zlib glaubt zu aktivieren, dies aber nicht im Bereich „protocol imap“ und nicht mit der „imap_zlib“-Einstellung tut, was dann dazu führt, dass mit der folgenden Fehlermeldung Mailboxen nicht abgerufen werden können:
Oct 13 16:16:08 hostname dovecot: imap(user): Error: read(/data/vmail/user/mdbox/storage/m.339): FETCH BODY[] for mailbox INBOX UID 505 got too little data: 2864 vs 6789
Mutmaßlich deshalb, weil der Server die Nachricht verschlüsselt schickt, dies aber nicht entsprechend announciert. Es muss, zur Lösung des Problems, das Plugin im Bereich „protocol imap {}“, bevorzugt in der Datei 20-imap.conf, wie folgt angegeben werden:
protocol imap {
mail_plugins = $mail_plugins imap_zlib
}
So, wie hier beschrieben.