Schon länger stand ich mit meinem persönlichen Bastel-NAS auf Kriegsfuß. Das Gerät stieg seit ca. 2 Jahren immer wieder unvermittelt aus. Einzelne Festplatten schalteten einfach ab.
Netzteil
Zuerst führte ich das auf Spannungsschwankungen durch ein defektes Netzteil zurück. Das unterdimensionierte 380 Watt Antec-Netzteil wich daher einem 750 Watt No-Name Ersatz, der zwar auch nicht die beste Lösung war, aber in meinem Lager lag und damit keine Zusatzkosten erzeugte.
Komische Anomalien und Hinweise
Eine Weile gab das System Ruhe. Bei parallelen Durchläufen von checkarray für das Software-RAID und gleichzeitigen Kopiervorgängen über rsync+ssh oder auch Samba wurden dann allerdings wieder Fehler ersichtlich. Erneut gab es Timeouts, teilweise gab es Kernel-Fehler, welche auf eine subtile Weise wieder auf I/O-Probleme hindeuteten.
Unabhängig davon traten immer wieder Fehler auf, welche auf RAM-Probleme hindeuteten, welche ich aber wiederholt fehlinterpretierte: Mehrfach ließen sich nach einem Reboot die LUKS-Partitionen nicht entschlüsseln obwohl der Schlüssel definitiv stimmte. Fehlermeldung lautete „No key available with this passphrase.“ – nach mehreren Versuchen und einiger Zeit funktionierte es dann plötzlich wieder.
Zudem traten diffuse Fehler z. B. mit dem APT-Paketmanager auf: Dieser konnte plötzlich keine Paketlisten herunterladen, obwohl es keine Fehlermeldungen gab – er hing schlicht bis man den Prozess beendete.
No-Name ASM1064 SATA-Controller ersetzt mit Avago LSI 9300 HBA
Da ich aufgrund der Ausfälle und der Symptome ein Problem mit der 1x PCIe Karte mit ASM1064 Chip vermutete, rüstete ich auf eine etwas professionellere Lösung mit LSI 9300 um. Der Performanceunterschied war riesig, aber Fehler traten immernoch auf. Uff.
Einzig richtige Entscheidung: memtester (online), memtest86+ (offline)
Im Betrieb des Gerätes startete ich mittels
memtester 8G 1
einen ersten Testdurchlauf. Schnell zeigten sich Speicherfehler. Keine einzelnen, „einfachen“ Bitflips, sondern teils Fehler über viele Bits hinweg. Zeit vollständig zu testen!
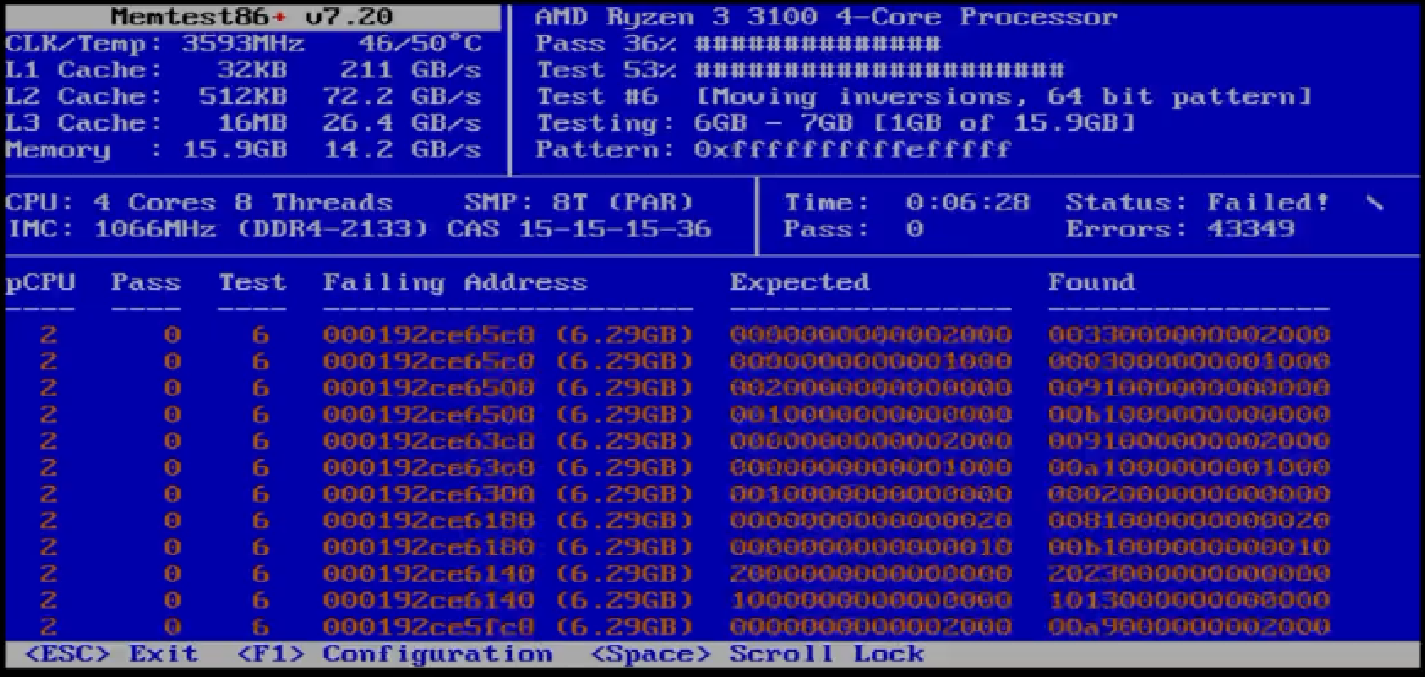
Also memtest86+ gestartet und den Speichertest laufen lassen. Sofort zeigten sich im Bereich um 6,29GB (insgesamt sind 16GB verbaut) zahlreiche Fehler. Der Fehler wurde damit gefunden.
Neuer RAM, halber RAM oder die defekten Bereiche im Linux-Kernel maskieren
Das passierte zu einem ungünstigen Zeitpunkt, da auch DDR4-Speicher preislich durch die Speicherkrise bei GDDR* und DDR5 beeinflusst sind. Ein einfacher 8GB-Riegel schlägt hier in billigster Ausführung und gebraucht mit 35€ zu Buche, sofern lieferbar, neu mit etwa 60€. Vernünftige Riegel liegen eher bei 100-120€. Autsch.
Die erste Alternative wäre eine Halbierung des Speichers von 16 auf 8GB. In meinem Anwendungsfall verkraftbar, aber vielleicht nicht in jedem. Mehr RAM ist halt mehr.
Die zweite Alternative: den defekten Speicherbereich mit ein bisschen Puffer einfach nicht nutzen. Dazu /etc/default/grub editieren:
GRUB_CMDLINE_LINUX="memmap=2G\\\$5G"
Im Beispiel deaktiviere ich 2GB ab 5GB, also den Bereich 5-7GB auf dem ersten RAM-Riegel. In diesen Bereich fällt der fehlerhafte Chip, welcher bei 6,29GB die Fehler produzierte. (Wichtig: 3 Backslashes mit aktuellem Ubuntu und GRUB, siehe hier!)
Daten verifzieren und reparieren
Bei Systemen ohne ECC führen Fehler im RAM durchaus zu Fehlern in geschriebenen Daten und zu Fehlern in Dateisystemen. ext4 ist hier weniger anfällig als z. B. btrfs, mit welchem ich vor etwa 10 Jahren bei einem RAM-Defekt schonmal mit einem heftig korrumpierten Dateisystem zu kämpfen hatte.
Dateisysteme verifizieren, eventuell reparieren und alle Bestandsdaten zur Probe lesen, ggf. nochmal Dateisystem verifizieren:
# Initialer fsck
e2fsck /dev/mapper/<Dateisystem>
# Alle Daten testweise lesen, Dateisystemfehler würden hier auffallen und das Dateisystem für fsck markiert werden
find /dein/pfad -type f -print0 | xargs -0 cat > /dev/null
# Sofern dmesg oder Konsole Fehler zeigen, oder wenn komische Anomalien auftreten nochmal:
e2fsck /dev/mapper/<Dateisystem>
Sind die Bestandsdaten leicht mit einer Sicherung oder einer verfügbaren Kopie abgleichbar, kann sich auch ein Resync dieser Daten lohnen.
Fazit
Ein bisschen Geld (ca. 112€ für LSI 9300 und Kabel) hätte ich durch eine bessere, umfassendere Fehleranalyse sparen können. Aber einen qualitativ höherwertigen HBA mit Portreserve (vorher 8, jetzt 16) zu besitzen, ist auch fein. Der Fehler wurde gefunden und kurzfristig behoben. Langfristig kann ich nun die DDR4-Speicherpreise beobachten und zu einem geeigneten Zeitpunkt zugreifen, um das System wieder zu vervollkomnen.
Schreibe einen Kommentar